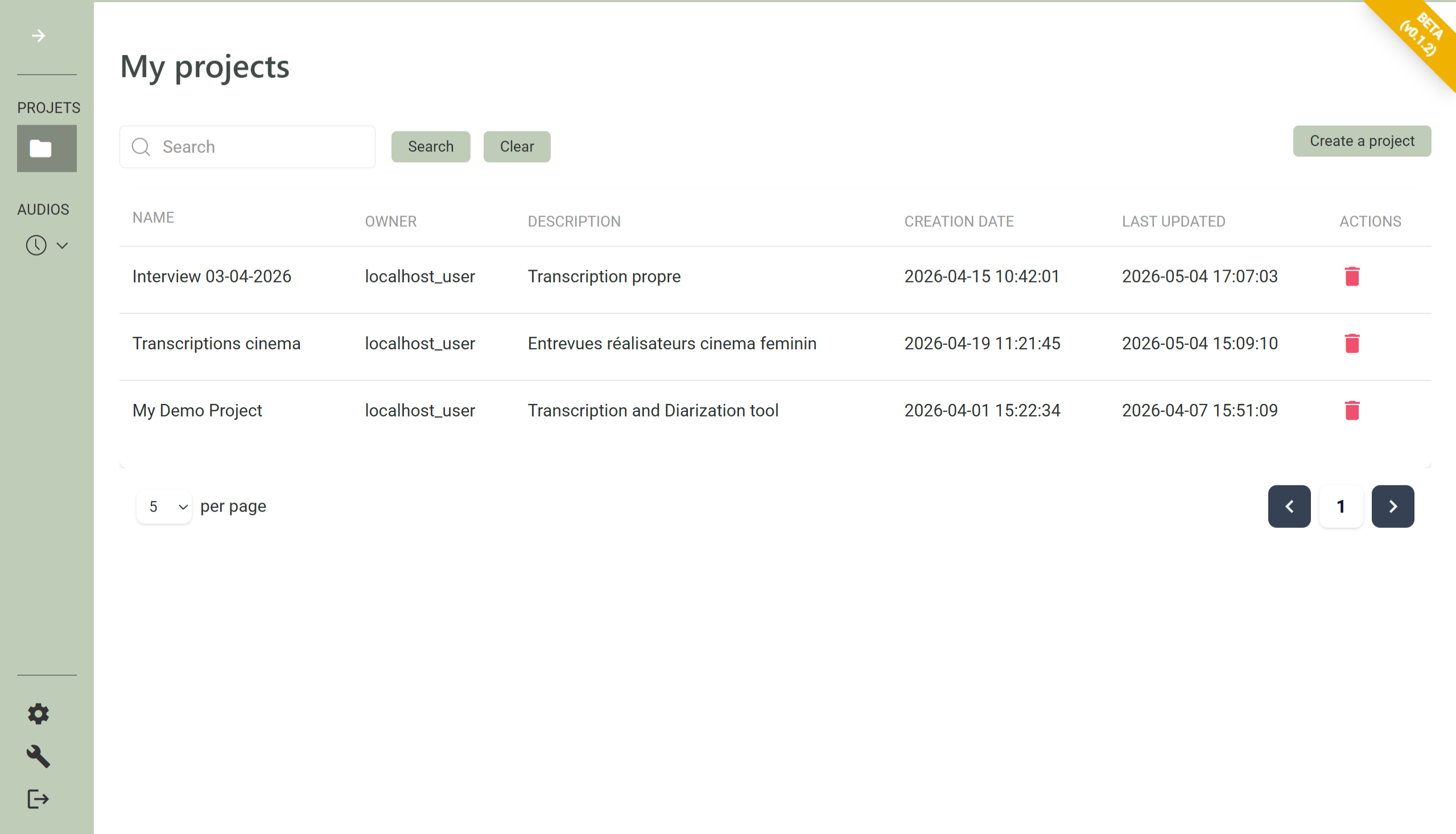
Turn interviews, focus groups, and field recordings into accurate text transcripts in minutes.
Whisper
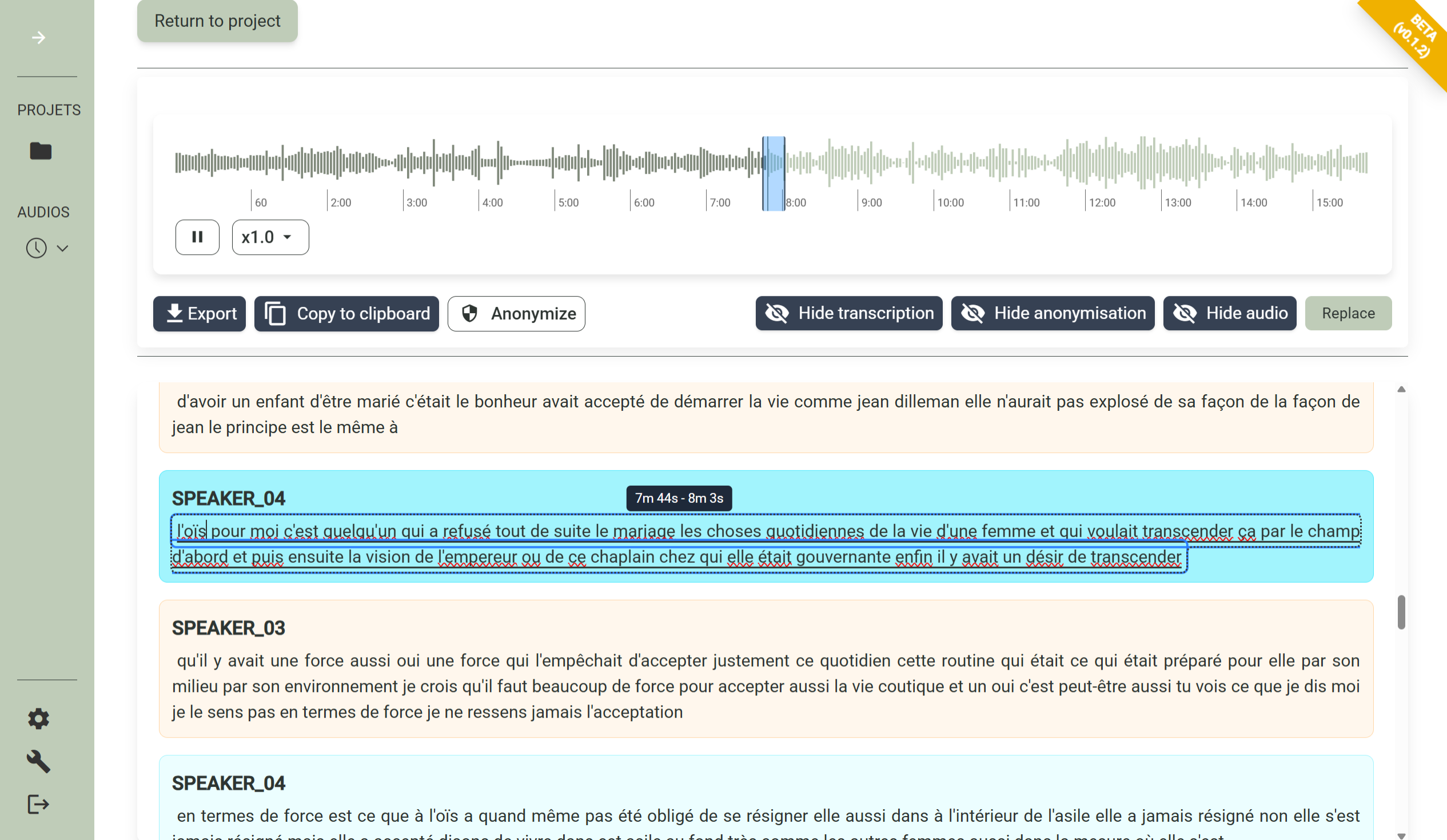
Tools for research and application workflow from raw audio to clean, structured transcripts.
Why Calame
Calame turns your interviews and field recordings into clean, structured transcripts with diarization, anonymisation, and full privacy.
Turn interviews, focus groups, and field recordings into accurate text transcripts in minutes.
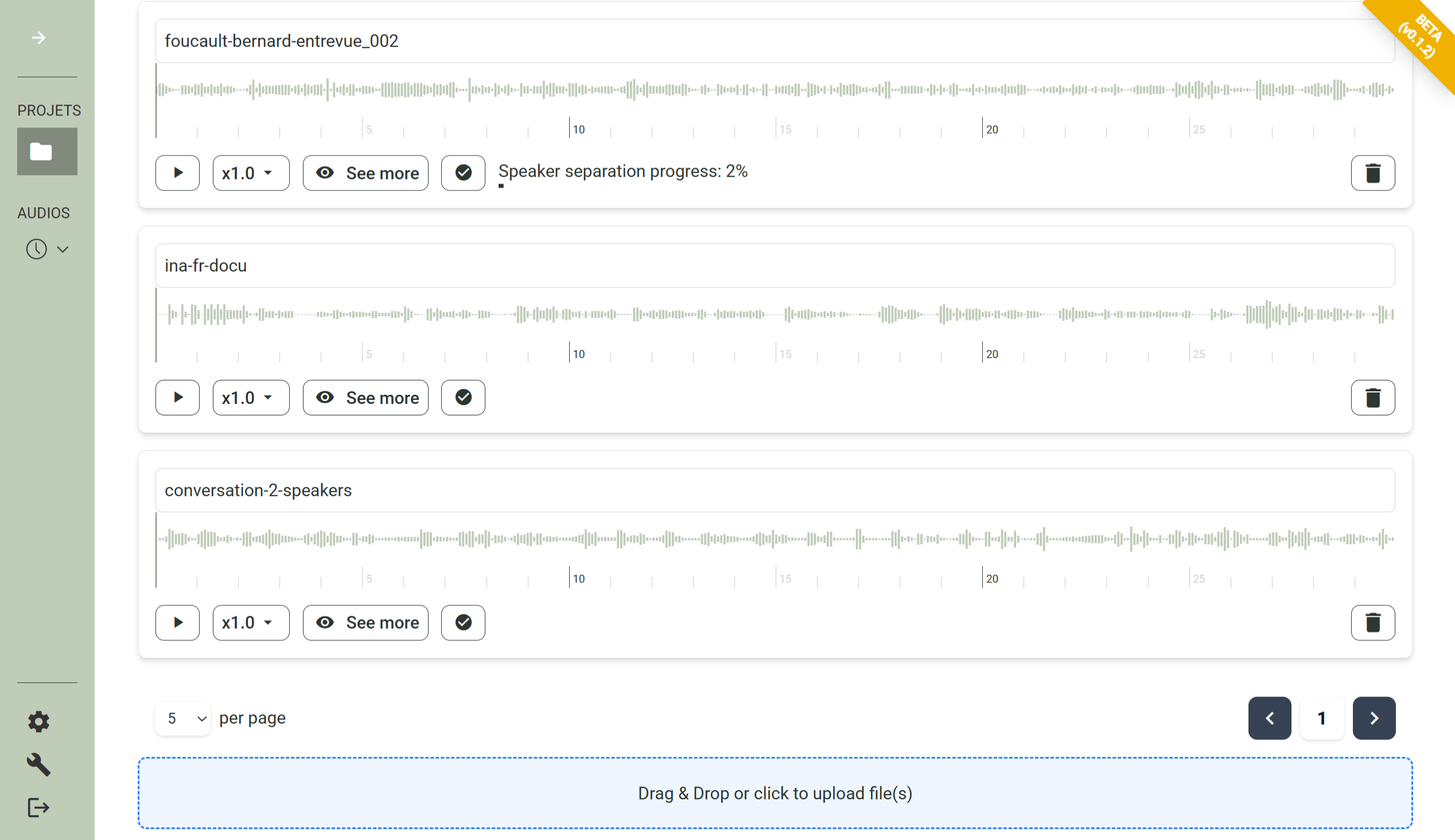
Automatically identify and label each speaker so you always know who said what.
Calame detects and redacts names, places, and identifying details to keep your participants protected.
All tools are open-source and available on ![]() Hugging Face
Hugging Face
Performance
| Hardware | File | tTRS | tDIA | t |
|---|---|---|---|---|
| i7-1260P | 5 min | 5.51 | 3.41 | 8.92 |
| 30 min | 26.34 | 22.72 | 49.06 | |
| 60 min | 51.31 | 39.45 | 90.76 | |
| RTX 2070 | 5 min | 3.24 | 0.39 | 3.63 |
| 30 min | 24.99 | 4.30 | 29.29 | |
| 60 min | 38.32 | 13.24 | 51.56 | |
| RTX 4060 | 5 min | 1.02 | 0.24 | 1.26 |
| 30 min | 3.72 | 1.36 | 5.08 | |
| 60 min | 6.99 | 2.83 | 9.82 |
System Requirements
12 GB
RAM
GPU / CPU
Supported
Docker
Environment
Future directions
Expanding first-class support beyond Québécois French to more dialects and low-resource languages.
Focus speaker identification on a single participant versus the full group, for interviews and one-on-one recordings.
Choose from multiple transcription or speaker separation models to improve accuracy across diverse audio conditions.
Share projects, review transcripts together, and manage team access for collaborative research workflows.
Our Partners


